Hydrocron is an API developed at PO.DAAC to enable time series analysis of hydrology features observed by the Surface Water and Ocean Topography (SWOT) satellite.
SWOT River data is archived and distributed as zipped shapefiles. These files are organized by passes of the SWOT satellite over continents, so each zip file contains many river features at one observation time. To analyze how a particular river is changing over time, you would then need to extract data for a single feature from many files. Hydrocron allows a user to specify the id of the single feature of interest, and will retrieve all of the observations for that feature in the time range specified.
How it works¶
Hydrocron is powered by AWS, using API Gateway, Lambda functions, DynamoDB tables, and SNS notifications. As data is ingested into the PO.DAAC archive, the shapefiles are unpacked and each river reach and node feature is added to a database. Users can then query the API for features using the known reach_id and node_id from the SWOT River Database (SWORD), as well as a time range of interest, and all observations within the time range of the feature of interest will be returned in geojson or csv format.
Hydrocron is an open source tool developed to support open science, and can be found on Github at https://
Full documentation describing the API parameters, available fields, and response codes is available at https://
Example 1 - Display a river reach on a map with geojson¶
import folium
import requests
from io import StringIO
import pandas as pd
import matplotlib.pyplot as pltSend a request to Hydrocron with the following parameters:
https://
feature=Reach
feature_id=53151000705
start_time=2024-01-01T00:00:00Z
end_time=2024-03-30T00:00:00Z
output=geojson
fields=reach_id,time_str,wse,width,geometry
hydrocron_response = requests.get(
"https://soto.podaac.earthdatacloud.nasa.gov/hydrocron/v1/timeseries?feature=Reach&feature_id=53151000705&start_time=2024-01-01T00:00:00Z&end_time=2024-03-30T00:00:00Z&output=geojson&fields=reach_id,time_str,wse,width,geometry"
).json()
hydrocron_response# extract just the geojson to plot on the map
geojson_data = hydrocron_response['results']['geojson']
geojson_data# Set up the map using Folium (https://python-visualization.github.io/folium/latest/)
map = folium.Map(tiles="cartodbpositron")
# add the geojson from Hydrocron to the map
folium.GeoJson(geojson_data, name='SWOT River Reach').add_to(map)
folium.LayerControl().add_to(map)
# zoom to the river feature we added
map.fit_bounds(map.get_bounds(), padding=(30, 30))
mapExample 2 - Time series analysis of river reach with CSV¶
Hydrocron also returns data in CSV format. Sending a similar request:
https://
feature=Reach
feature_id=53151000705
start_time=2024-01-01T00:00:00Z
end_time=2024-03-30T00:00:00Z
output=csv
fields=reach_id,time_str,wse,widthTip: if you don’t need to plot the feature on a map, omit the geometry field to make the response size smaller
hydrocron_response = requests.get(
"https://soto.podaac.earthdatacloud.nasa.gov/hydrocron/v1/timeseries?feature=Reach&feature_id=53151000705&start_time=2024-01-01T00:00:00Z&end_time=2024-03-30T00:00:00Z&output=csv&fields=reach_id,time_str,wse,width"
).json()
hydrocron_response{'status': '200 OK',
'time': 671.337,
'hits': 9,
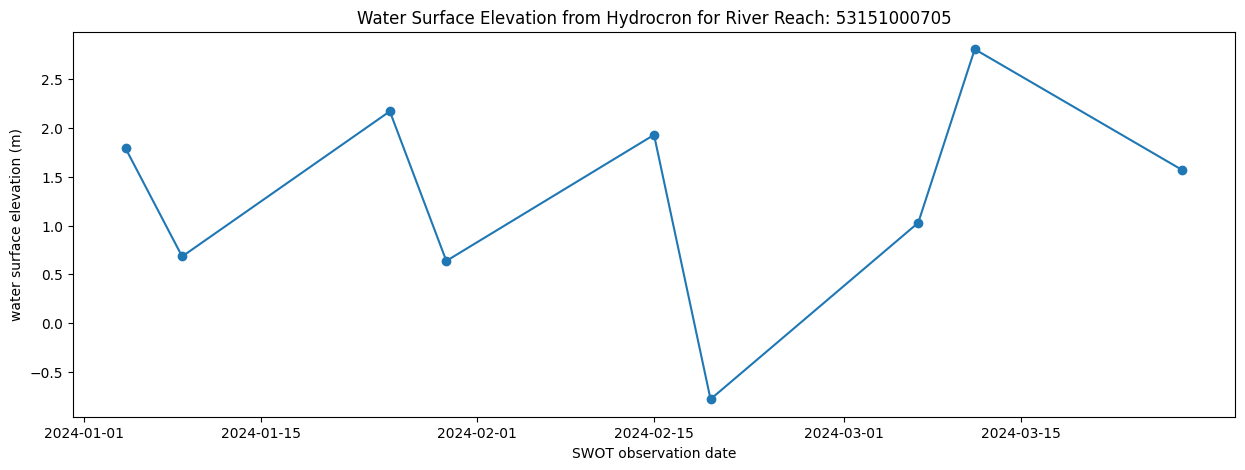
'results': {'csv': 'reach_id,time_str,wse,width,wse_units,width_units\n53151000705,2024-01-04T06:37:03Z,1.7907,50.806911,m,m\n53151000705,2024-01-08T17:42:49Z,0.6825,52.609886,m,m\n53151000705,2024-01-25T03:22:09Z,2.1713,114.208752,m,m\n53151000705,2024-01-29T14:27:55Z,0.637,53.039506,m,m\n53151000705,2024-02-15T00:07:14Z,1.9299,91.767635,m,m\n53151000705,2024-02-19T11:13:00Z,-0.7814,57.307131,m,m\n53151000705,2024-03-06T20:52:18Z,1.0285,58.796301,m,m\n53151000705,2024-03-11T07:58:04Z,2.8083,49.727437,m,m\n53151000705,2024-03-27T17:37:21Z,1.5681,57.518117,m,m\n',
'geojson': {}}}
csv_str = hydrocron_response['results']['csv']
csv_str
'reach_id,time_str,wse,width,wse_units,width_units\n53151000705,2024-01-04T06:37:03Z,1.7907,50.806911,m,m\n53151000705,2024-01-08T17:42:49Z,0.6825,52.609886,m,m\n53151000705,2024-01-25T03:22:09Z,2.1713,114.208752,m,m\n53151000705,2024-01-29T14:27:55Z,0.637,53.039506,m,m\n53151000705,2024-02-15T00:07:14Z,1.9299,91.767635,m,m\n53151000705,2024-02-19T11:13:00Z,-0.7814,57.307131,m,m\n53151000705,2024-03-06T20:52:18Z,1.0285,58.796301,m,m\n53151000705,2024-03-11T07:58:04Z,2.8083,49.727437,m,m\n53151000705,2024-03-27T17:37:21Z,1.5681,57.518117,m,m\n'df = pd.read_csv(StringIO(csv_str))
dfdf.time_str = pd.to_datetime(df.time_str)fig = plt.figure(figsize=(15,5))
plt.plot(df.time_str, df.wse, marker='o')
plt.ylabel('water surface elevation (m)')
plt.xlabel('SWOT observation date')
plt.title('Water Surface Elevation from Hydrocron for River Reach: ' + str(df.reach_id[0]))